Shared-Everything Architecture vs. Shared-Nothing Architecture
This post compares the two architectures and the basic principles for choosing the right one
In a previous post, we discussed the basics of ClickHouse and the challenges presented in two cases, following which we considered the shared storage architecture, which is also called the disaggregated compute and storage architecture, as shown in Figure 1.
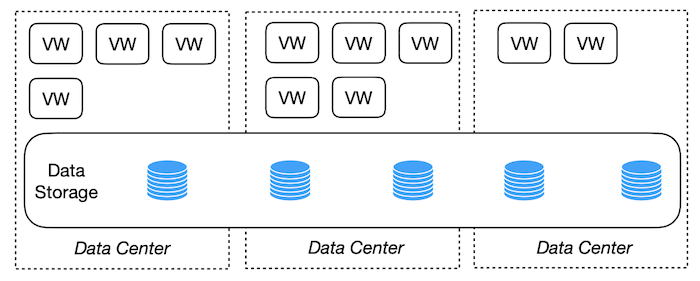 Figure 1. Disaggregated compute and storage architecture
Figure 1. Disaggregated compute and storage architecture
As shown in this figure, there are many computing resources, and they are isolated from the data storage. Computing resources will see a global shared pool which is the data storage layer. This means all of the data in this pool can be shared across all computing resources.
This architecture has three major advantages.
Advantages of Shared-everything Architecture
Better elasticity: Computing resources and the storage are isolated and they can be scaled independently based on the demand for the resources. If we want more computing resources, we can add more computing instance; if we need more data storage, we can expand the volume for the data storage layer.
Better scalability: As the data can be shared, theoretically, we can scale out to utilise as many computing resources as possible.
Ease of use: Cluster managers don't need to worry about the data consistency, data replica, and data charging; and all of these can be delegated to the data storage. For example, companies can utilise the Amazon S3 to store the data.
Disadvantages of Shared-everything Architecture
However, this disaggregated computing architecture does have its disadvantages. Because the computing and the data storage are separated, it has extra latency for the remote access.
Since each architecture has its pros and cons, how do we select the proper architecture for your company's unique requirements. Let’s compare the two on four aspects as shown in Table 1.
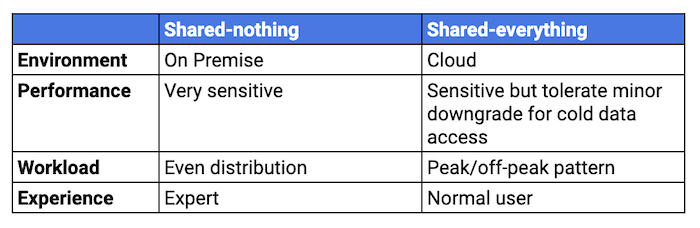 Table 1: Share-nothing architecture vs. Shared-everything architecture
Table 1: Share-nothing architecture vs. Shared-everything architecture
Environment. For “shared-nothing” architecture, on-premises hardware resources are relatively stable as you cannot increase or decrease them frequently. For “shared-everything” architecture, the cloud infrastructure allows much higher degree of elasticity based on users’ demand.
Performance. The “shared-nothing” architecture has very good performance. While “shared-everything” architecture has good performance, users should be able to tolerate minor downgrade for cold data access. We will discuss about ways to improve this in the later part of the article.
Workload. If the work load is evenly distributed at any time, you can utilise your resources fully and there is no waste. Then, you can consider the shared-nothing architecture.
If your workload often sees some spike with the peak and off-peak pattern, you should consider the shared everything architecture. To best utilise your resources, you can scale up or scale down efficiently, which can significantly reduce the cost.
Experience. Using ClickHouse requires some expertise with a strong background or terminology on the operation or maintenance of this cluster. In the shared-everything architecture, because you can delegate some challenges to the existing system, it doesn't require strong domain knowledge.
These are some basic principles for choosing data warehouse architecture. We'll explore cloud-native ClickHouse and how we implement it at ByteDance in the next post.
About the author: Niu Zhaojie obtained his PhD from Nanyang Technological University in Singapore. Currently, he is a senior software engineer at Bytedance and building analytics database in cloud.