Exploring Cloud-Native ClickHouse
Cloud-native ClickHouse can utilise resources efficiently and reduce the infrastructure cost
In a previous post, we shared a comparison of shared-everything and shared-nothing architecture and how to choose between these two architectures. In this post, we'll share about cloud-native ClickHouse.
There were three main objectives for building cloud-native ClickHouse (CNCH).
The first objective was to support the disaggregated compute and storage architecture natively so that we can use the resources more efficiently, and reduce monetary costs.
The second objective was to enable containerisation. We wanted to make all our computing resources in containers so that we could utilise container orchestration platforms like Kubernetes to help us manage clusters. Also, containerisation has a large adoption, which means it has a better ecosystem. Future expansion to different cloud providers that support Kubernetes becomes easy, and we don't have to worry about the lower level environment of the system.
Last but not least, we want to optimise our system to be more user friendly and reduce operation cost.
Multi-layer abstraction
We have some abstractions on cloud-native ClickHouse and it consists three layers as shown in Figure 1.
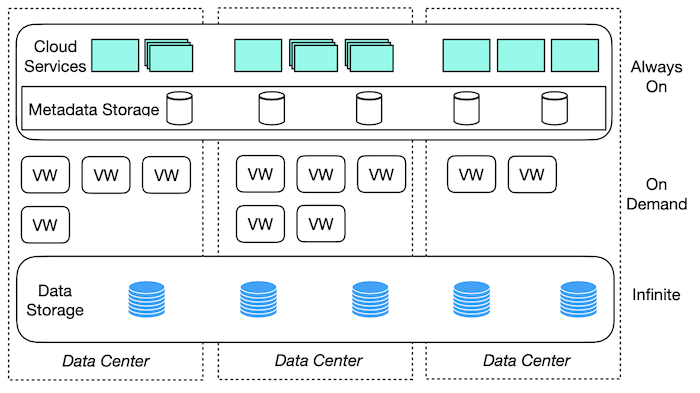
Figure 1. Disaggregated Compute and Storage
The first layer is a cloud service. User will directly communicate with this layer, we must guarantee it is always on so that the user can use the query service at any time.
The second layer is virtual warehouse layer. It is responsible for computing. This layer is on demand so that we can scale up based on users' requirement or the demand.
The last layer is data storage and it should be expanded according to the data volume.
Implementations
In this section, we introduce the implementation of CNCH. Figure 2 shows all components inside the system.
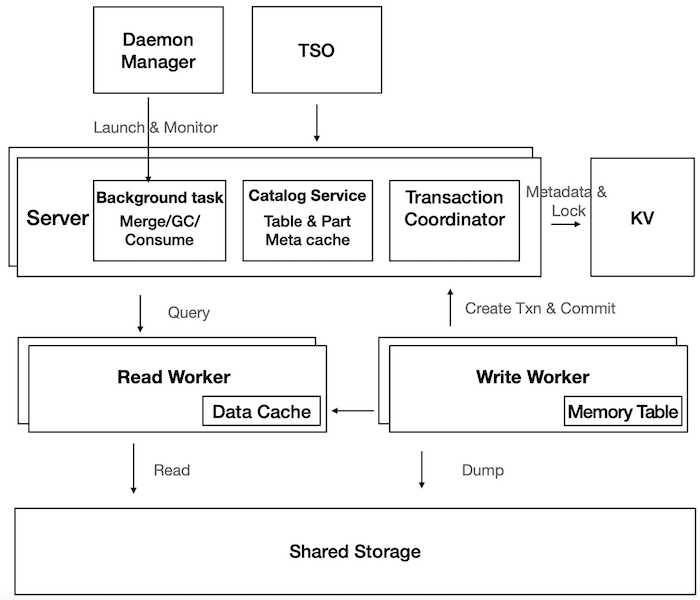
Figure 2. Cloud Native ClickHouse Overview
The computing resources include the servers and the workers. The users will directly send queries to the server. After the server accepts the queries, the server is responsible for scheduling the queries and assign the tasks to different workers. There are two different kinds of workers: the READ worker and the WRITE workers. The READ worker is mainly responsible for SELECT and the WRITE worker is mainly responsible for INSERT. By having this disaggregated architecture, we can even have more kinds of workers, such as dedicated workers for background tasks.
We manage the metadata in the distributed key-value store. The data is stored in the shared storage. The shared storage in Figure 2 can be HDFS, S3, and other distributed storage systems.
Now let's take a look how a select query is executed in CNCH . It mainly consists of 3 steps as shown in Figure 3 below:
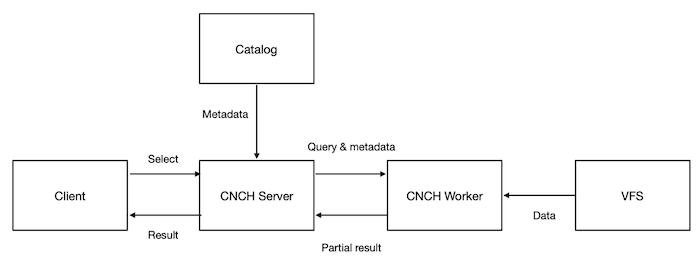
Figure 3. SELECT Execution in Cloud ClickHouse
When CNCH server receives the query from the client, it first gets part metadata from the catalog and then distributes sub queries and parts to different workers for execution.
For each worker, after it receives the subqueries from the server, it reads data from Virtual File System (VFS), performs computing and send the result back to the server.
The server performs a final aggregation based on the results get from workers and send the final results to the client
For the write query, it's the opposite process of select query which is shown in Figure 4,
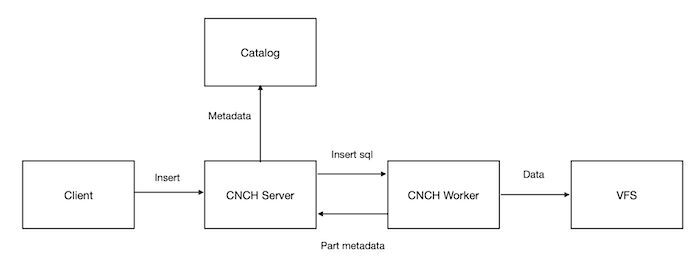
Figure 4. INSERT execution in Cloud-native ClickHouse
When the server receives the INSERT SQL, it directly forwards to the write worker.
The write worker writes the data to the virtual file system (VFS).
Once the data is written to the VFS successfully, server commits those part to the catalog side and notify the client when finishes.
In CNCH, users don't need to be aware of how the metadata&data are managed. All of these are transparent and CNCH automatically handles everything for the users. So users only need to send the query to the CNCH and CNCH will be responsible for scheduling, allocation, execution and storage for this query.
Challenges Introduced by The New Architecture
Remote access
In previous sections, I mentioned the new architecture has some disadvantages such as performance downgrade caused by remote data access. For this issue, we leverage cache to solve it. We have metadata cache on the server side and data cache on the worker side.
Virtual filesystem abstraction
In order to support different underlying data storage systems in different clouds. We proposes a virtual filesystem layer on top of the underlying storage systems.
Metadata Management
In order to manage our metadata more efficiently and properly, we introduce transaction semantic in cloud-native ClickHouse and provide ACID guarantee in the metadata management.
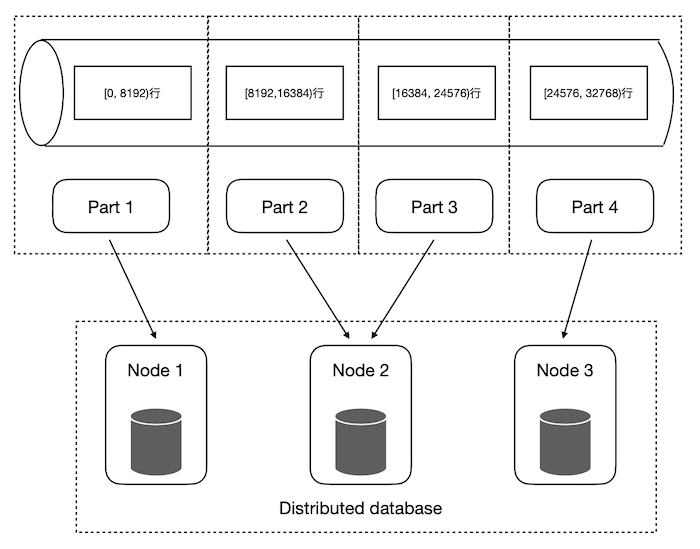
Figure 5. Transaction Support
As shown in Figure 5, we have a large amount of data and all of the data will be translated to multiple parts. We manage the parts in a global shared metadata storage layer. How do we make sure all the parts can be seen at the same time is quite challenging. After we have the transaction support, we can guarantee the atomic properties.
We also provide concurrency control and read committed isolation level to guarantee the data correctness under the concurrent read and write scenarios. To further improve the performance for concurrent read and write, CNCH leverages multi version (MVCC) in metadata management.
Conclusion
On top of the new disaggregated compute and storage architecture, cloud-native ClickHouse can utilise resources more efficient and reduce the infrastructure cost. And, it performs query scheduling automatically to different virtual warehouse and leverage Kubernetes to manage the clusters, it significantly reduces the operation and maintenance cost. By leveraging cache, efficient metadata and data management, the cloud-native ClickHouse achieves very competitive performance as ClickHouse.
About the author: Niu Zhaojie obtained his PhD from Nanyang Technological University in Singapore. Currently, he is a senior software engineer at Bytedance and building analytics database in cloud.