What is ClickHouse? Leverage ClickHouse to speed up your data analysis
Companies like Uber, eBay, Spotify enhanced query performances and significantly reduced costs
ClickHouse* is an open source column-oriented database management system designed primarily for the use of online analytical processing (OLAP).
In June 2016, the project was made available as an open-source software under the Apache 2 license.
What is ClickHouse good for?
You might wonder what ClickHouse is good for and why use a column-oriented database?
Column-oriented databases are more suited to OLAP applications since only a few table columns must be read for an analytical query. You only read the data you need in a column-oriented database.
Data is simpler to compress since it in columnar format, and is read in packets. This decreases the I/O volume even further. More data fits in the system cache because of the decreased I/O.
ClickHouse works 100-1000x faster than traditional approaches, according to ClickHouse's official data. And, it can process over a billion rows and tens of gigabytes of data per server per second.
When to use ClickHouse
As a typical OLAP engine with column-based storage, ClickHouse is suitable for scenarios that satisfy the following requirements::
Large amount of batch insertions
Little or no modification on existing data
Wide table with lots of columns
Aggregation computation on selected columns
Fast SELECT queries
You need to be cautious when it involves the following:
OLTP usage, in which UDPATE and Transaction support is a must
Key-Value like storage and single row query
Over-normalised data, which requires many JOIN operations during query
Blob or document storage
ClickHouse Architecture
Let's take a look at the architecture of ClickHouse.
ClickHouse has shared-nothing architecture in which the computing resource and the storage resource are tightly coupled as shown in Figure 1:
 Figure 1: ClickHouse's shared-nothing architecture
Figure 1: ClickHouse's shared-nothing architecture
Each machine has its own data and the data is not shared across different servers. The shared-nothing architecture has its pros and cons.
The advantage is that it's super fast because of local access. In theory, the only limiting factors are the hardware resources of servers. However, because the computing resource and the storage resource are tightly coupled, there are two major disadvantages.
First, shared-nothing architecture limits the elasticity since the computing resource and storage resource cannot be scaled independently.
For example, when we don't need some computing resources, we still need to keep these servers on in order to make the data on them available, unless we copy that data to other servers. The cost of copying data can't be ignored, which prevents the system from scaling on demand.
Second, the data cannot be shared among servers, which leads to bad scalability as shown in Figure 1. If the data of one query only exists in one server, the query performance can not be further improved even if we add more servers.
Challenges
At some large technology enterprises such as ByteDance, applications expand and change extremely fast. There's a very strong requirement on cluster scaling. Let's take a look at two cases.
 Figure 2: Server movement
Figure 2: Server movement
The first case is shown in Figure 2. When cluster 2 needs more resources and cluster 1 has some free resources, cluster 2 can borrow some resources from cluster 1. For example, 2 servers are moving from cluster 1 to cluster 2.
We need to move data C and D on the 2 servers to remaining servers in cluster 1. Then, after moving the 2 servers to cluster 2, rebalancing of data also needs be performed in order to use them. There is extra high data copy and rebalance cost on the server movement, and we may miss the best time to do the cluster scaling.
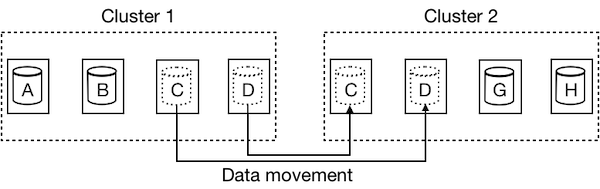 Figure 3: Data movement
Figure 3: Data movement
The second case is shown in Figure 3. Instead of migrating servers, we want to migrate applications to from cluster 1 to cluster 2. On the shared-nothing architecture, we have to move its data C and D first and then migrate the applications. The migration cost is very high when the data size is large.
Can we utilise the shared storage architecture to solve this problem? Can we support the shared-nothing architecture natively? By keeping these questions in mind, we start to explore shared-everything architecture, which you can read here.
Related eBook (free download): Reimagine ClickHouse
About the author: Niu Zhaojie obtained his PhD from Nanyang Technological University in Singapore. Currently, he is a senior software engineer at Bytedance and building analytics database in cloud.
*ClickHouse is a trademark of ClickHouse, Inc.