What does it take to ensure high availability in ClickHouse? Metadata persistence
ByteHouse ensures high availability by reducing pressure on Zookeeper and metadata persistence
ClickHouse availability issues encountered by ByteDance
In its early stages, ByteDance used the enterprise version of ClickHouse for data warehousing. With the rapid expansion of its business and product portfolios, the number of ClickHouse cluster nodes supporting the operations also burgeoned. Daily partitioning increased rapidly, with one cluster managing an unusually large number of libraries and tables, and metadata inconsistencies emerged. The combination of the two factors caused the cluster's availability to drop extremely quickly, to the point where it became unacceptable for operations.
Three main issues emerged:
Frequent breakdowns
Hardware failures occurred almost every day, and as the cluster grew in size, ZooKeeper exceeded its capacity, increasing the frequency of failures.
Longer recovery time
When a failure occurred, the recovery time routinely exceeded an hour, which was completely unacceptable.
Increased operational complexity
Previously, only one person handled cluster operations; however, as the number of nodes and partitions increased, the complexity and difficulty of cluster operations grew exponentially. The number of staff had to be increased, and yet it remained difficult to ensure the cluster's stability.
Because low availability became a major obstacle to business growth, ByteHouse worked to identify and solve all issues to ensure high availability.
ByteHouse's solutions to ensuring High Availability
Reduce pressure on Zookeeper
The ReplicatedMergeTree engine is used by ClickHouse to synchronise data. ReplicatedMergeTree, which enables leader election among replicas, data synchronisation, and fault recovery, is conceptually based on ZooKeeper. Because ReplicatedMergeTree actively utilises ZooKeeper, it may store a sizable amount of data, including logical logs, partition related info, and some table level metadata for each set of replicas.
ZooKeeper performs poorly under high loads because it doesn't scale well linearly. It can't write replicas or synchronise data in that case. So, ZooKeeper quickly became a bottleneck.
Optimisation: ReplicatedMergeTree supports insert_quorum. If the number of replicas is 3 and insert_quorum=2, at least two replicas have to be successfully written before returning successful acknowledgement.
Figure 1 shows the flow of a new partition being replicated.
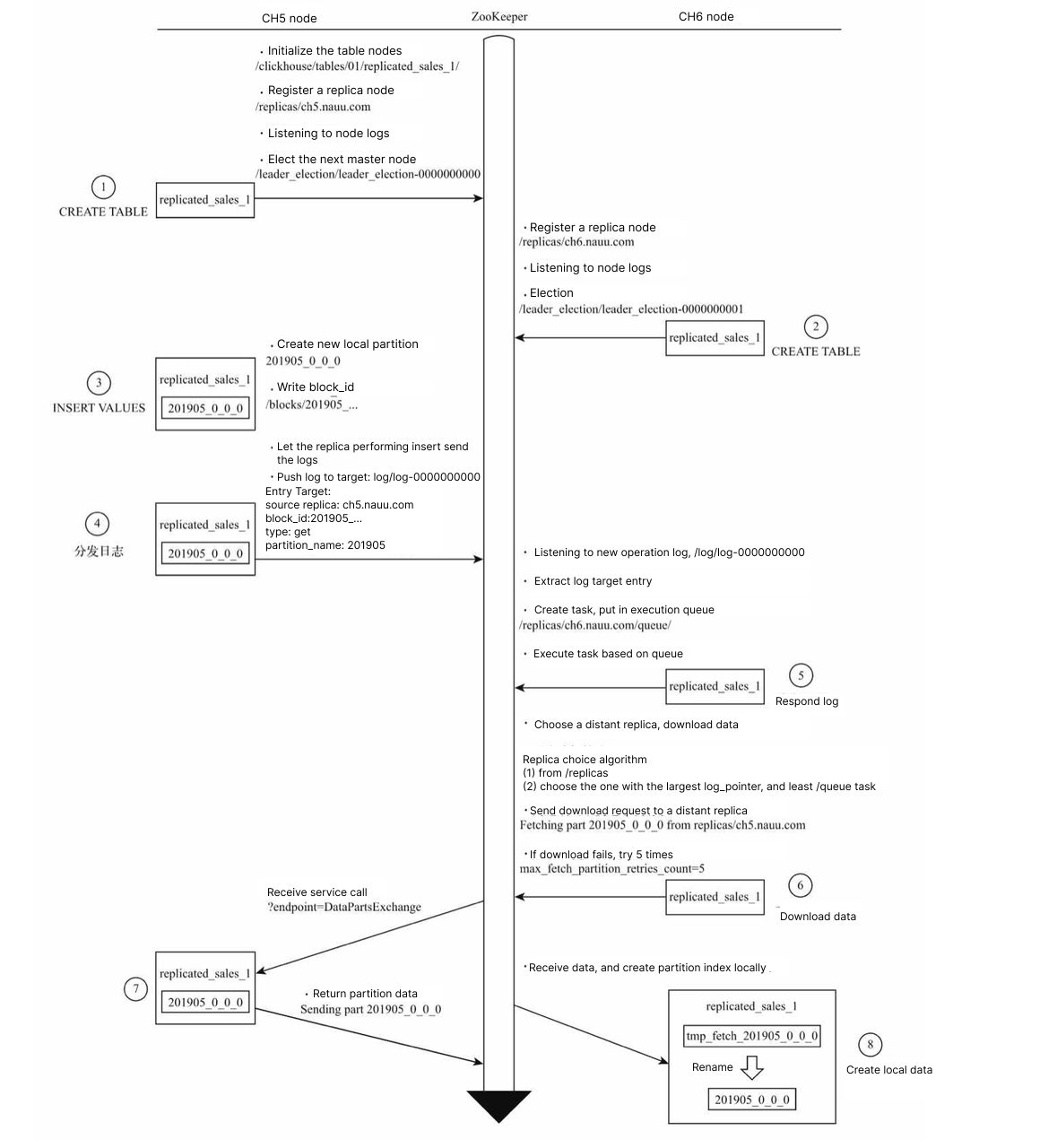 Figure 1. Flow of a new partition being replicated
Figure 1. Flow of a new partition being replicated
As you can see, one underlying reason for the bottleneck was the recurring dissemination of logs and exchange of data via Zookeeper.
In order to reduce the load on ZooKeeper, a HaMergeTree engine was implemented at ByteHouse, which reduced the number of requests to as well as the amount of data stored on ZooKeeper.
The new HaMergeTree synchronisation engine:
Kept table level metadata on ZooKeeper
Simplified the distribution of logical logs
Removed partition information from ZooKeeper logs
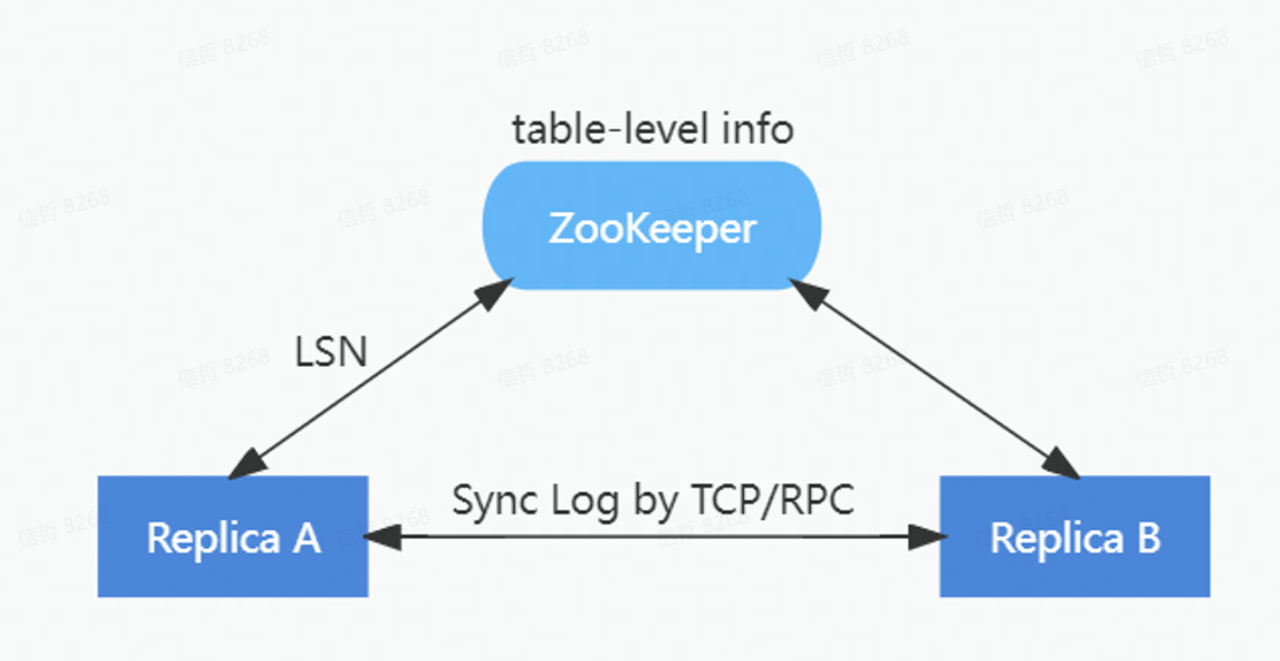 Figure 2. HaMergeTree synchronisation engine
Figure 2. HaMergeTree synchronisation engine
HaMergeTree reduced the load on Zookeeper by reducing the amount of information it stored, only log LSNs, with the specific logs being replicated between replicas via the gossip protocol.
The new HaMergeTree significantly lessened the stress on ZooKeeper while maintaining complete compatibility with ReplicatedMergeTree, making the load on the ZooKeeper cluster independent of data volume.
The number of downtimes caused by Zookeeper decreased significantly after HaMergeTree went live. Whether it was a single cluster with hundreds or thousands of nodes, or a single node with tens of thousands of tables, stability was guaranteed.
Improve fault resilience
Despite all the efforts made by data practitioners to keep their online production environments trouble free, it is difficult to avoid encountering a variety of problems such as:
Software defects - bugs in software design that cause abnormal terminations, or problems with component compatibility
Hardware failures - disk corruption, memory failure, CPU failure, etc. The frequency of failures increases linearly as the cluster size increases
Memory leak terminates processes - a frequent issue with OLAP databases
Unexpected factors - problems caused by power failure, misuse, etc.
To achieve good performance, ClickHouse stores metadata in the memory, resulting in a very long time for the server to restart. As a result, when a failure occurs, the recovery time is also very long, approximately one to two hours, leading to a long business interruption. When failures occur on a regular basis, the resulting business loss is incalculable.
Optimisation: In order to solve the above problem, ByteHouse uses a metadata persistence solution, where RocksDB acts as a metadata storage backend and the server loads metadata directly from RocksDB on startup, and only the necessary Part information is stored in memory. This reduces the memory consumption of metadata and speeds up cluster startups and shortens recovery time.
As shown in the diagram below, metadata persistence is implemented using RocksDB plus Meta in Memory, with each table corresponding to the Part metadata of the tables in the RocksDB database. When the table is first started, the metadata loaded from the filesystem persists in RocksDB; subsequent restarts allow the Part to be loaded directly from RocksDB.
Memory will only store some necessary information for each Part loaded from RocksDB or the file system to a table. The Part metadata stored in memory is called to read and load the corresponding Part from RocksDB.
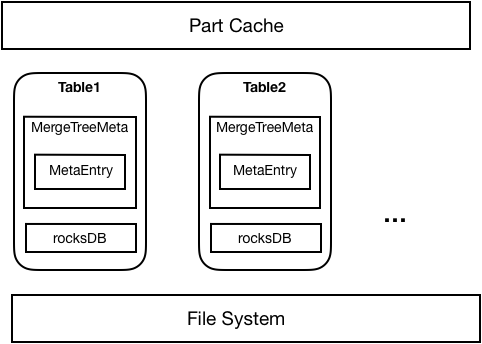 Figure 3. Implementing metadata persistence
Figure 3. Implementing metadata persistence
With the completion of metadata persistence, the number of partitions supported on a single server is no longer limited by memory capacity and can exceed 1 million with little to no performance loss.
Recovery times for failures are significantly reduced, taking only a few tenths of the time previously required. For example, a recovery time of one to two hours on ClickHouse takes only three minutes on ByteHouse, significantly improving system availability and providing solid business support.
Besides the above two points, ByteHouse's availability has also been enhanced by improving the high availability of data writes through the HaKafka engine, improving the fault tolerance of real-time data writes, automatically switching between primary and backup writes, and adding a monitoring and maintenance platform to enable monitoring and alerting of key indicators. The platform also includes several diagnostic tools to aid rapid identification of faults.
The stability of data analysis platforms is critical. ByteHouse will continually improve its high availability, and provide the strongest stability guarantee with the highest performance.