The Modern Data Stack - An essential guide
Your guide to the modern data stack and how you can build one using ByteHouse
Modern Data Stack. Sorry, what?
So, everyone and their pet have a tech stack. Folks in the data world have ‘modern data stacks’. But, what exactly does that mean?
A modern data stack (MDS) refers to a set of technologies and tools that organisations use to collect, process, store, and analyse data in a way that is agile, scalable, and aligned with contemporary data processing needs. The stack typically includes components such as cloud-based storage, data processing frameworks, managed services, and tools for analytics and business intelligence. The goal is to provide a flexible and efficient infrastructure that supports the dynamic and complex requirements of today’s data-driven businesses.
Seriously, what are we stacking?
Everything written above sounds very nice, but surely, a stack must be made of components.
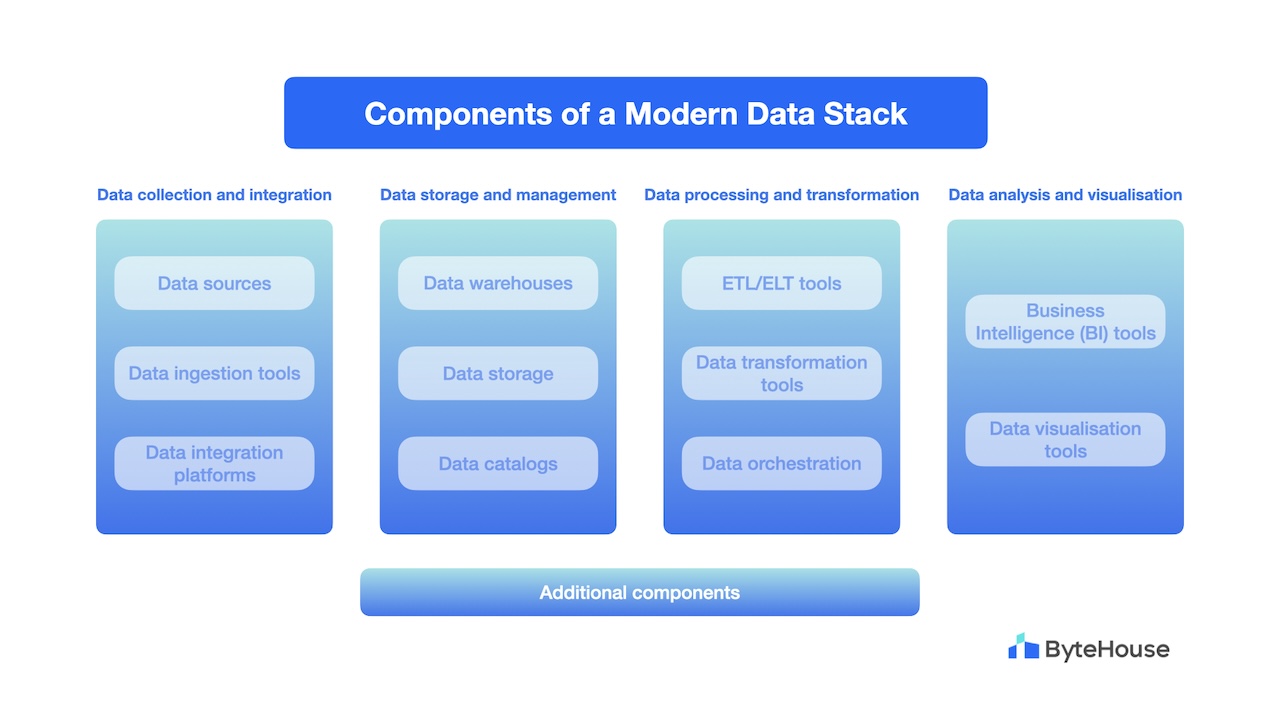
Of course! There are components. These are the broad categories in which they fall.
Data collection and integration:
Data sources: Raw data originates from diverse sources, such as applications, databases, logs, interconnected devices, and external APIs. These sources feed the data stack with information.
Data ingestion tools: These tools capture data from various sources, including databases, event streams, APIs, and IoT devices.
Data integration platforms: These platforms unify data from different sources into a single format and location for further processing.
Data storage and management:
Data warehouses: These are centralised repositories where large volumes of structured, cleaned, and transformed data are stored for analysis.
Data storage: Besides data warehousing, cloud-based storage solutions are used for cost-effective and scalable storage of raw or semi-structured data. These repositories can also be used to build data lakes.
Data catalogs: These tools organise and manage data assets, making them easier to discover and use.
Data processing and transformation:
ETL/ELT tools: These tools extract, transform, and load data into the target data store.
Data transformation tools: These tools clean, format, and prepare data for analysis.
Data orchestration: These platforms automate and schedule data workflows, ensuring the seamless execution of data pipelines.
Data analysis and visualisation:
Business Intelligence (BI) tools: These tools enable users to explore and analyse data through interactive dashboards and reports.
Data visualisation tools: These tools create visual representations of data, such as charts and graphs, to communicate insights effectively.
Additional components:
Data governance and security tools: These tools ensure data quality, compliance, and access control. And they protect data from unauthorised access and breaches.
Machine Learning and Artificial Intelligence (AI) tools: These tools can be used to analyse data and extract insights that may be difficult to identify with traditional methods.
Cloud services: Cloud platforms are often the foundation of modern data stacks, providing scalable infrastructure, managed services, and cost-effective solutions.
This cohesive integration of components forms a robust modern data stack, empowering organisations to derive actionable insights and make informed decisions based on their data.
So, what makes these data stacks ‘modern’?
Good question. Modern data stacks differ from traditional data stacks on several key characteristics. They often leverage cloud-native architecture, focus on scalability, and embrace diverse data types and processing paradigms.
Here are a few things that make these data stacks ‘modern’:
Cloud-based: Modern data stacks leverage cloud computing platforms. This provides scalability, flexibility, and reduced IT infrastructure costs compared to on-premises solutions. They often use serverless or containerised services.
Horizontal scaling: Modern data stacks are designed to scale horizontally, handling growing data volumes and processing demands through distributed computing. Traditional data stacks typically rely on vertical scaling of hardware, which is both expensive and inflexible.
Data variety and flexibility: Modern data stacks accommodate diverse data types, including structured, semi-structured, and unstructured data, as opposed to traditional data stacks that primarily deal with structured data. The storing of raw data allows the building of data lakes for future analysis, enabling exploration and discovery of previously unknown patterns.
Data processing paradigms: Modern data stacks embrace batch processing and real-time/streaming processing, and real-time data pipelines to support timely insights and immediate action based on current data. Traditional data stacks often rely heavily on batch processing.
Managed services: Modern data stacks utilise managed services for data storage, processing, and analytics, reducing the operational burden on teams.
Embracing open-source and excellence: Modern data stacks incorporate open-source tools and best-of-breed solutions from multiple vendors. This promotes flexibility and avoids vendor lock-in.
Agile and iterative: Modern data stacks emphasise rapid development and deployment with continuous integration and delivery (CI/CD) practices. This agile approach enables faster data insights and quicker adaptation to changing needs.
Data democratisation: Modern data stacks empower more users with self-service analytics tools and simplified data access. This encourages collaboration and broader data-driven decision-making within the organisation.
Machine learning and AI integration: Modern data stacks integrate machine learning and AI tools to automate data analysis, predict future trends, and extract deeper insights from complex data.
These characteristics collectively define the agility, scalability, and flexibility that distinguish a modern data stack from its traditional counterpart, aligning with the demands of today’s dynamic data landscape.
Building a Modern Data Stack with ByteHouse
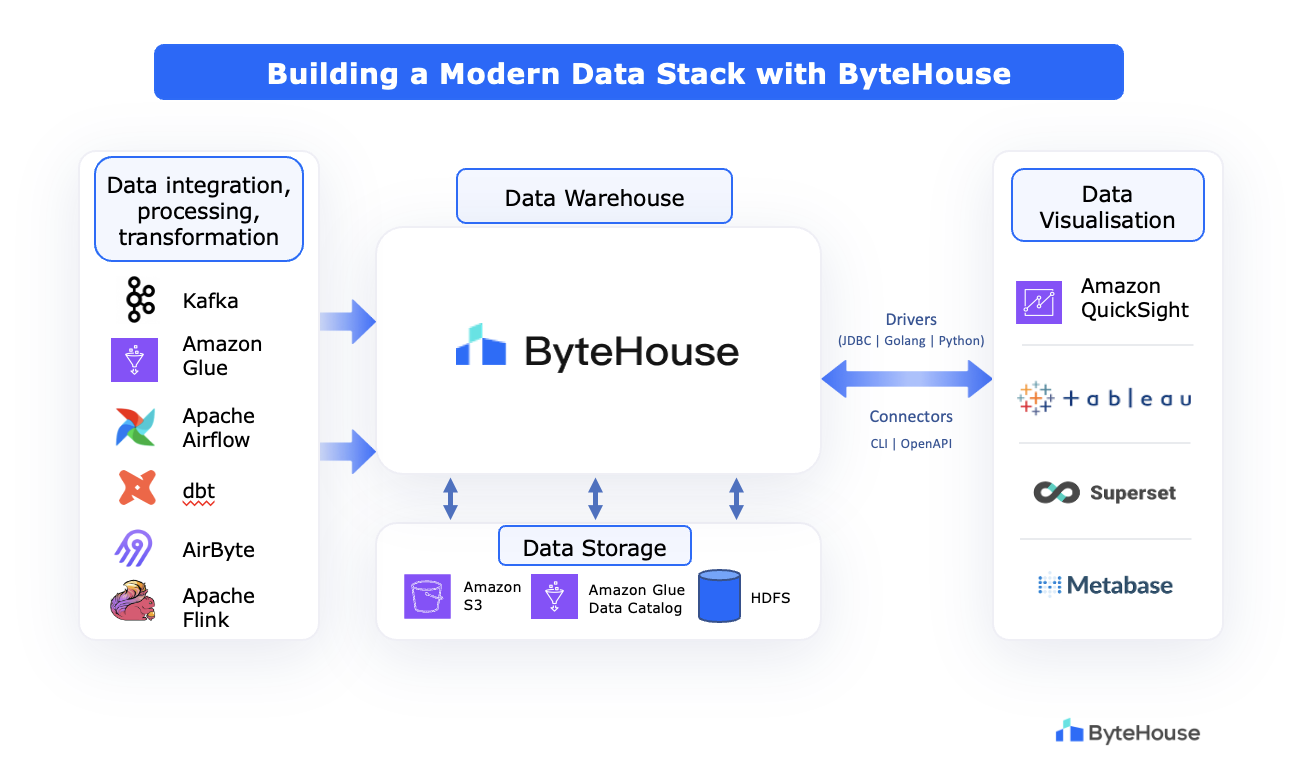
ByteHouse offers a powerful foundation for building a modern data stack due to its capabilities for handling real-time and batch data, high performance, and scalability. It provides several connectors like the JDBC/ODBC, Go, and CLI that help you integrate with a wide variety of open-source and enterprise tools to build your data stack. Here's how you can do it:
Data collection and integration:
ByteHouse can connect with multiple data sources and can ingest both streaming and batch data from IoT devices, applications, sensors, relational databases, cloud storage, and other sources. It seamlessly integrates with Apache Kafka, Flink, Amazon Glue and Apache Airflow.
Data storage and management:
ByteHouse is a cloud native data warehouse that can be deployed on AWS for storage and management of both real-time and historical data. It can directly connect with object storage solutions like Amazon S3 and HDFS for data archiving and cost-effective storage of large datasets. By integrating with catalog systems such as Apache Hive Metastore (HMS) or AWS Glue, ByteHouse gains the ability to leverage their powerful metadata management capabilities.
Data processing and transformation:
ByteHouse provides robust connectivity with ETL/ELT, data transformation and data orchestration tools. You can utilise Apache Airflow, dbt, Airbyte, and Apache Flink here.
Data analysis and visualisation:
ByteHouse can connect with BI and visualisation tools like Tableau, Datawind, and Apache Superset to create custom visualisations, interactive dashboards and reports.
In addition to the above, ByteHouse implements role-based access control to govern data access and ensure security. It also provides connectivity with SQLAlchemy and Data Grip to help you build a complete ecosystem.
Building a modern data stack with ByteHouse requires careful planning and execution. You are welcome to reach out to us to consult with data architects and engineers to design a data stack that meets your specific needs and ensures optimal performance, scalability, and security.