10 use cases of a data lakehouse for modern businesses
Exploring the use cases for a data lakehouse and how to build one
A data lakehouse is a contemporary data architecture that merges the attributes of a "data lake" and a "data warehouse." This approach offers a cohesive method for storing, governing, and analysing data within an organisation.
The concept of a data lakehouse seeks to bridge the gap between a data lake and a data warehouse. It amalgamates the adaptability of a data lake with the speed and organisation advantages of a data warehouse. This implies that data is stored in its raw form (akin to a data lake), yet it's also systematically organised and indexed to facilitate rapid querying and analysis (similar to a data warehouse).
A data lakehouse offers modern businesses a transformative edge by uniting the adaptive prowess of a data lake with the structured efficiency of a data warehouse. This fusion optimises data storage, processing, and analysis, enabling agile decision-making. It caters to advanced analytics, real-time reporting, data science, and business intelligence needs, while ensuring data integrity, governance, and diverse workload support. The architecture empowers businesses with timely insights, personalised customer experiences, historical trend analysis, and agile data exploration, enhancing competitiveness and unlocking new opportunities for data monetisation. Ultimately, a data lakehouse drives informed strategies, streamlined operations, and innovation across industries.
Use cases
These are the most prevalent use cases for a data lakehouse:
Advanced analytics: A data lakehouse is ideal for conducting advanced analytical tasks that involve processing diverse data types, including structured and unstructured data. This encompasses tasks like predictive analytics, sentiment analysis, and anomaly detection, providing valuable insights into business operations.
Real-time reporting: The architecture's support for end-to-end streaming empowers organisations to generate real-time reports and dashboards. This aids in monitoring key performance indicators (KPIs) and promptly responding to emerging trends or anomalies.
Data science and machine learning: With its versatility in supporting varied workloads, a data lakehouse becomes a playground for data scientists and machine learning practitioners. The availability of diverse data types enables the development and deployment of advanced models for prediction, classification, and recommendation systems.
Business Intelligence (BI): By facilitating the direct use of BI tools on source data, a data lakehouse streamlines the process of generating insights from raw data. This expedites decision-making and enhances the accuracy of business strategies.
Historical data analysis: The time travel feature of a data lakehouse allows historical data views, aiding in historical trend analysis, compliance reporting, and long-term performance evaluation.
Regulatory compliance and data governance: The architecture's governance and metadata management capabilities contribute to maintaining data quality and enforcing consistent standards across the organisation. This is crucial for compliance, regulatory reporting, and data integrity.
Agile data exploration: Data analysts and business users can engage in agile data exploration, swiftly accessing and analysing diverse datasets. This promotes informed decision-making and empowers teams to adapt to changing market conditions.
Customer 360 views: A data lakehouse allows for the integration of structured transactional data and unstructured customer interactions, enabling the creation of comprehensive customer 360-degree views. This facilitates personalised marketing and customer relationship management.
IoT data processing: With the ability to handle large volumes of streaming data, a data lakehouse is well-suited for processing Internet of Things (IoT) data. This involves analysing sensor data, monitoring device performance, and predicting maintenance needs.
Data monetisation: Organisations can leverage the data lakehouse to refine, process, and analyse their data, creating opportunities to monetise data assets through data-as-a-service offerings, market insights, and customer segmentation.
In essence, a data lakehouse caters to a wide array of use cases, offering a versatile and comprehensive solution to address the multifaceted data needs of modern businesses.
How ByteHouse can help you build a data lakehouse
ByteHouse provides the following features to help you build your own data lakehouse solution.
Query Amazon S3 directly using ByteHouse
The ByteHouse S3 External Table Feature allows users to easily create external tables based on data stored in Amazon S3 buckets. With this feature, users can seamlessly create and query external tables without having to load data into the ByteHouse database.
This reduces data loading time, minimises storage costs, and simplifies data management. The S3 External Table feature also provides users with the ability to query large datasets, making it a powerful addition to the platform.
Integration with AWS Glue, Hive
In lakehouse architecture, the catalog system acts as a central repository for storing and managing metadata, including table schemas, column details, partitions, and other relevant information. It serves as a crucial bridge between the operational and analytical aspects of data processing, providing an automatic way to keep up with schema evolution.
By integrating with catalog systems such as Apache Hive Metastore (HMS) or AWS Glue, ByteHouse gains the ability to leverage their powerful metadata management capabilities. This integration allows ByteHouse to perform efficient data discovery, query optimisation, and compatibility with external tools and frameworks
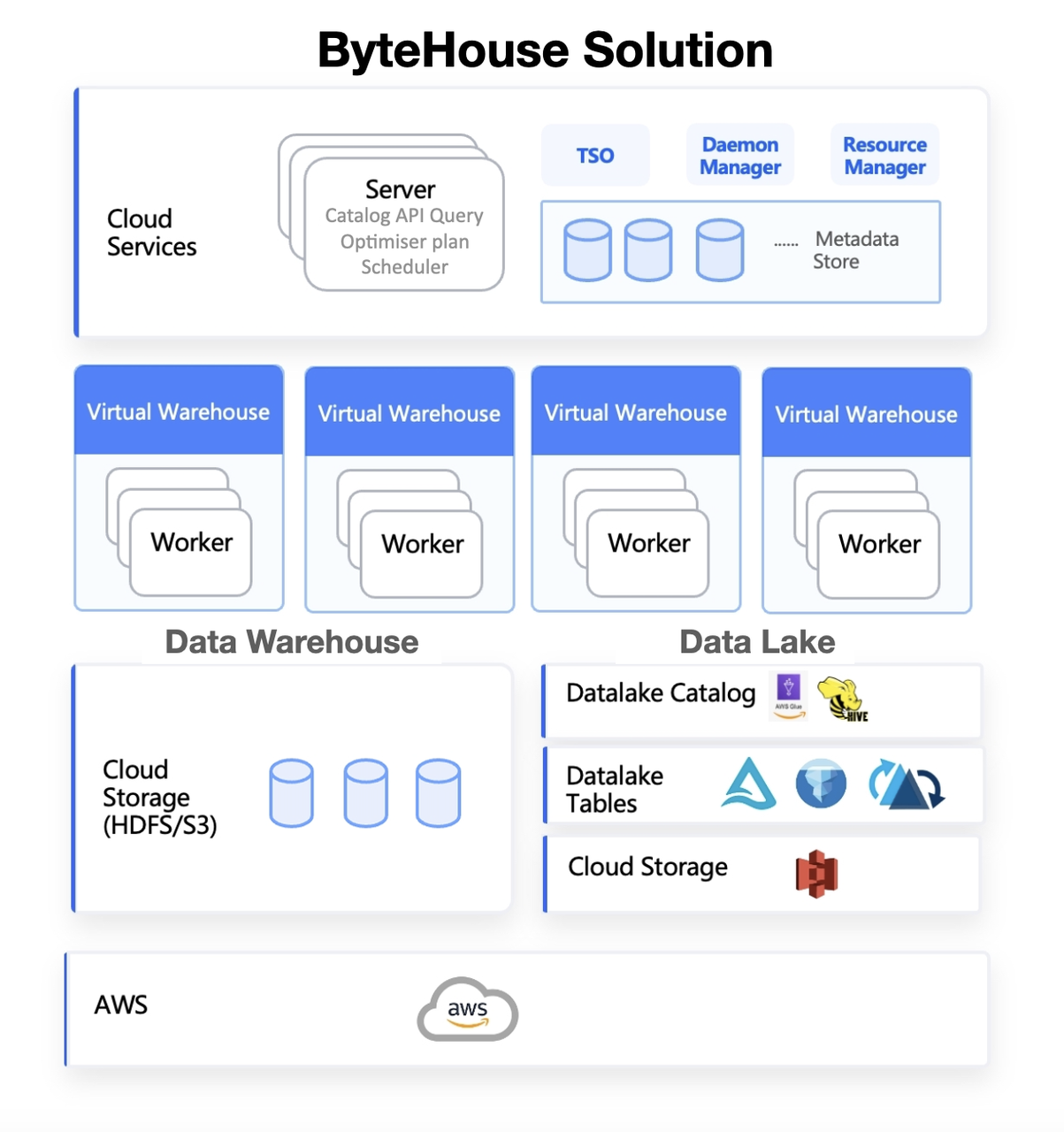
ByteHouse data lakehouse solution
ByteHouse R&D is also working hard to integrate with Iceberg and you should be seeing a launch announcement from us soon!