Data modelling techniques: Navigating the complexities
Part 4 out of 5 of 'Data Modelling: Unlocking Insights, One Model at a Time' series
This blog post is Part 4 of ByteHouse's 5-part series titled Data Modelling: Unlocking Insights, One Model at a Time
This series will cover the following topics:
Data modelling techniques
Benefits of data modelling
Data modelling, as we know, is the process of creating a visual representation of data, its relationships, and its attributes. It is an essential step in data management and analysis, as it helps to ensure that data is organised in a way that is efficient, accurate, and easy to understand.
Over the years, several data modelling techniques have been created, each having its own set of pros and cons. The most common data modelling techniques include hierarchical data models, relational data models, entity-relationship (ER) data models, object-oriented data models, dimensional data models, and graph data models.
This blog post will cover data modelling techniques, discussing their features, benefits, and limitations. We will also provide examples of how each technique can be used to model real-world data.
Evolution of data modelling techniques
The first data modelling techniques emerged in the 1960s and 1970s, as businesses began to collect and store large amounts of data. These early techniques were based on hierarchical data models, which represent data in a tree-like structure.
Hierarchical data models were simple to implement and understand, but they were not very flexible. They were also difficult to use for complex data queries.
In the 1980s, relational data models emerged as a more flexible and powerful data modelling technique. Relational data models store data in tables, which are linked together by relationships. This allows for more complex and efficient data queries.
Relational data models quickly became the standard for data modelling in most industries. However, they are not well-suited for all types of data, such as unstructured data and semi-structured data.
To address the limitations of relational data models, new data modelling techniques have emerged in recent years, such as object-oriented data models, dimensional data models, and graph data models.
Data modelling techniques
1. Hierarchical data models
Hierarchical data models represent data in a tree-like structure, with each node having one or more child nodes. Hierarchical data models are simple to implement and understand, but they can be difficult to use for complex data queries, limiting their versatility in modern data applications.
Hierarchical data models are often used to model data that has a natural hierarchical structure, such as a file system or an organisation chart.
2. Relational data models
Relational data models, a breakthrough in the 1970s, store data in tables, which are linked by relationships. Data is organised into tables with rows and columns, and relationships are established using keys. This model was popularised by relational database management systems (RDBMS).
Relational data models are more flexible and powerful than hierarchical data models, and they are well-suited for a wide range of data modelling applications.
Relational data models are the standard for data modelling in most industries. They are used in a wide range of applications, including database systems, data warehouses, and data marts.
3. Entity-relationship (ER) data models
ER data models focus on entities, their attributes, and the relationships between entities. These graphical representations provide a clear visualisation of the data structure, aiding in understanding complex relationships within a dataset. ER models are widely used for conceptual design in database development and may be used as a starting point for designing relational database schemas.
ER data models are easy to understand and use, and they can be used to model complex data relationships. However, they can be difficult to maintain as the data domain changes.
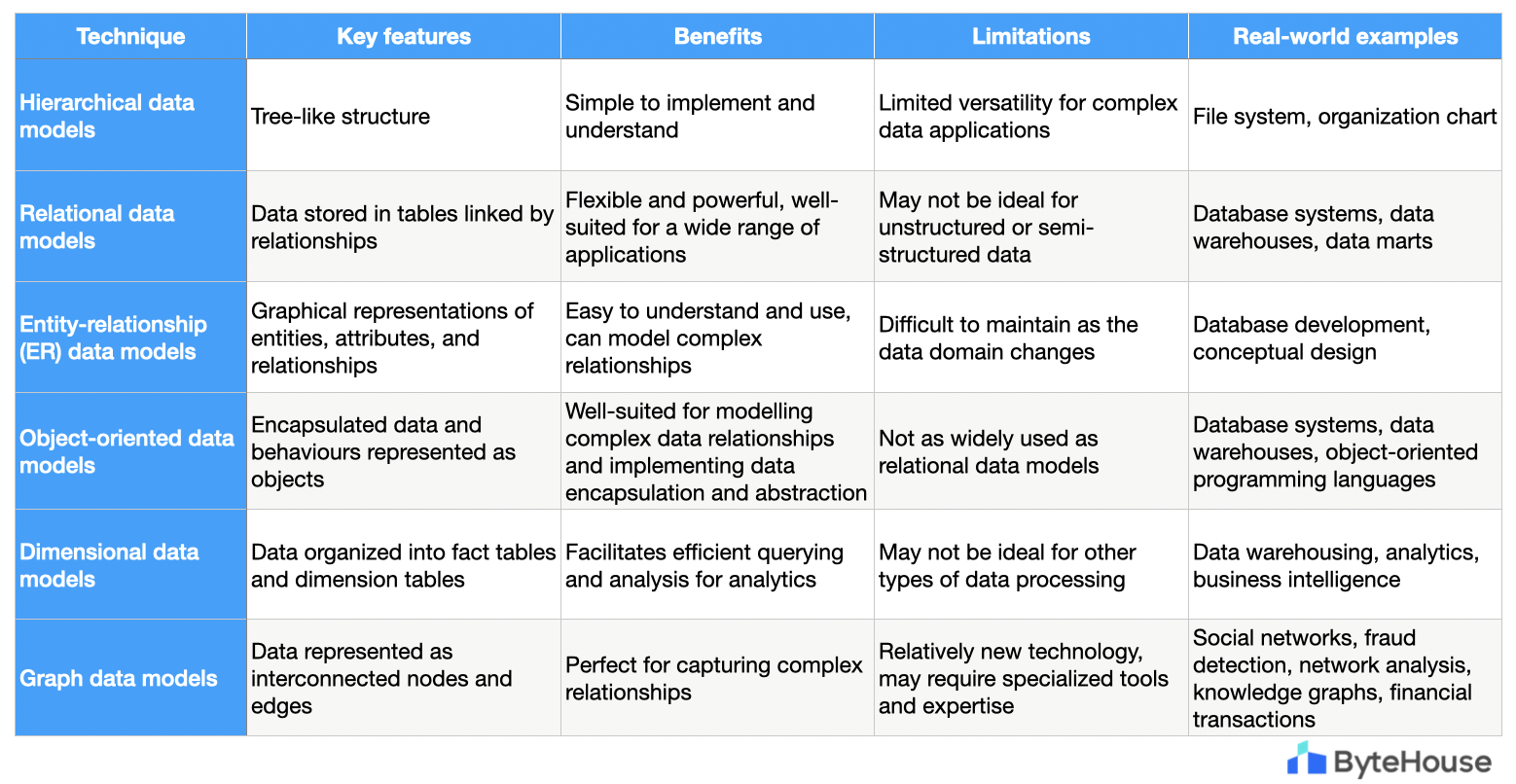 Summary of data modelling techniques
Summary of data modelling techniques
4. Object-oriented data models
Object-oriented data models extend the principles of object-oriented programming to data. In this model, data entities are treated as objects, encapsulating data and behaviours. The objects have properties and methods.
Object-oriented data models are well-suited for modelling complex data relationships and for implementing data encapsulation and abstraction. They are often used in database systems, data warehouses, and object-oriented programming languages.
5. Dimensional data models
Dimensional data models are specialised structures used in data warehousing, analytics, and business intelligence. These models organise data into fact tables and dimension tables, facilitating efficient querying and analysis.
Dimensions provide context, and facts contain the numerical data, enabling multidimensional analysis of business data. Dimensional data models are well-suited for modelling data that is used for analytics, such as sales data, customer data, and financial data.
6. Graph data modelling
Graph data models represent data as interconnected nodes and edges, perfect for capturing complex relationships. These models excel in scenarios like social networks, fraud detection, network analysis, knowledge graphs, and financial transactions. Nodes represent entities, and edges denote relationships, creating a powerful representation of intricate connections within datasets.
Graph data modelling is a relatively new technology, but it is becoming increasingly popular for modelling big data and complex data relationships.
Data modelling is an essential step in data management and analysis. Each technique has its unique strengths, making it crucial to choose the right model based on the specific requirements of your project.
As data engineering continues to advance, being well-versed in these techniques equips professionals with the tools necessary to tackle diverse and intricate data challenges. Whether you're handling structured business data or exploring the depths of interconnected relationships, understanding these models empowers you to navigate the complexities of the data landscape with confidence.