Basics of data modelling and data models
Part 1 out of 5 of 'Data Modelling: Unlocking Insights, One Model at a Time' series
Data Modelling: Unlocking Insights, One Model at a Time
Beginning this week, ByteHouse will be sharing a 5-part series on Data Modelling. This series will offer a deep dive into the following topics:
Basics of data modelling and data models
Data modelling vs. data architecture
The data modelling process
Data modelling techniques
Benefits of data modelling
This blog post is part 1 of the series.
Imagine a sprawling library without a catalogue system, where books are strewn haphazardly, making finding anything a Herculean task. In the intricate landscape of data engineering, data modelling is the meticulous curator that designs the pathways and categorises the information.
At its core, data modelling is the process of creating a visual representation of data structures. Imagine it as crafting a detailed roadmap that guides your data on its journey from raw information to valuable insights. This process involves defining the data, its structure, and the relationships between various data elements. Data modelling is pivotal in transforming chaotic data into an organised, meaningful format that businesses can leverage effectively.
Significance
Data modelling holds immense significance in the data-driven landscape of today. By creating a structured blueprint, it enables businesses to comprehend their data better. This understanding is crucial for informed decision-making, strategic planning, and gaining competitive advantages. Moreover, data modelling streamlines the development of databases, ensuring efficient storage, retrieval, and manipulation of data. It connects raw data with actionable insights, allowing organisations to unlock patterns, forecast trends, and make data-backed decisions, thereby fostering innovation and growth.
Data Models: Levels of abstraction
There are three primary levels of abstraction and detail in the data modeling process:
Conceptual Data Model: At the initial stage, conceptual models provide a high-level view of the entire data architecture. They focus on understanding the business requirements and the relationships between different entities. Think of it as a rough sketch, outlining the basic structure without delving into technical details.
Logical Data Model: Moving a step further, logical models define how data elements relate to one another without considering the specific database management system. This level of modelling focuses on defining entities, their attributes, and the relationships between them, providing a detailed yet abstract view of the data structure.
Physical Data Model: Here, the focus shifts to the implementation details. Physical models delve into specifics such as data types, indexing, and storage considerations. It is at this stage that the model takes real shape, paving the way for the actual database creation.
Sometimes, we also use a fourth level called dimensional modelling. Often used in data warehousing, dimensional modelling focuses on organizing and structuring data for easy and efficient querying and reporting. It revolves around the creation of fact and dimension tables, optimising data for analytical processing.
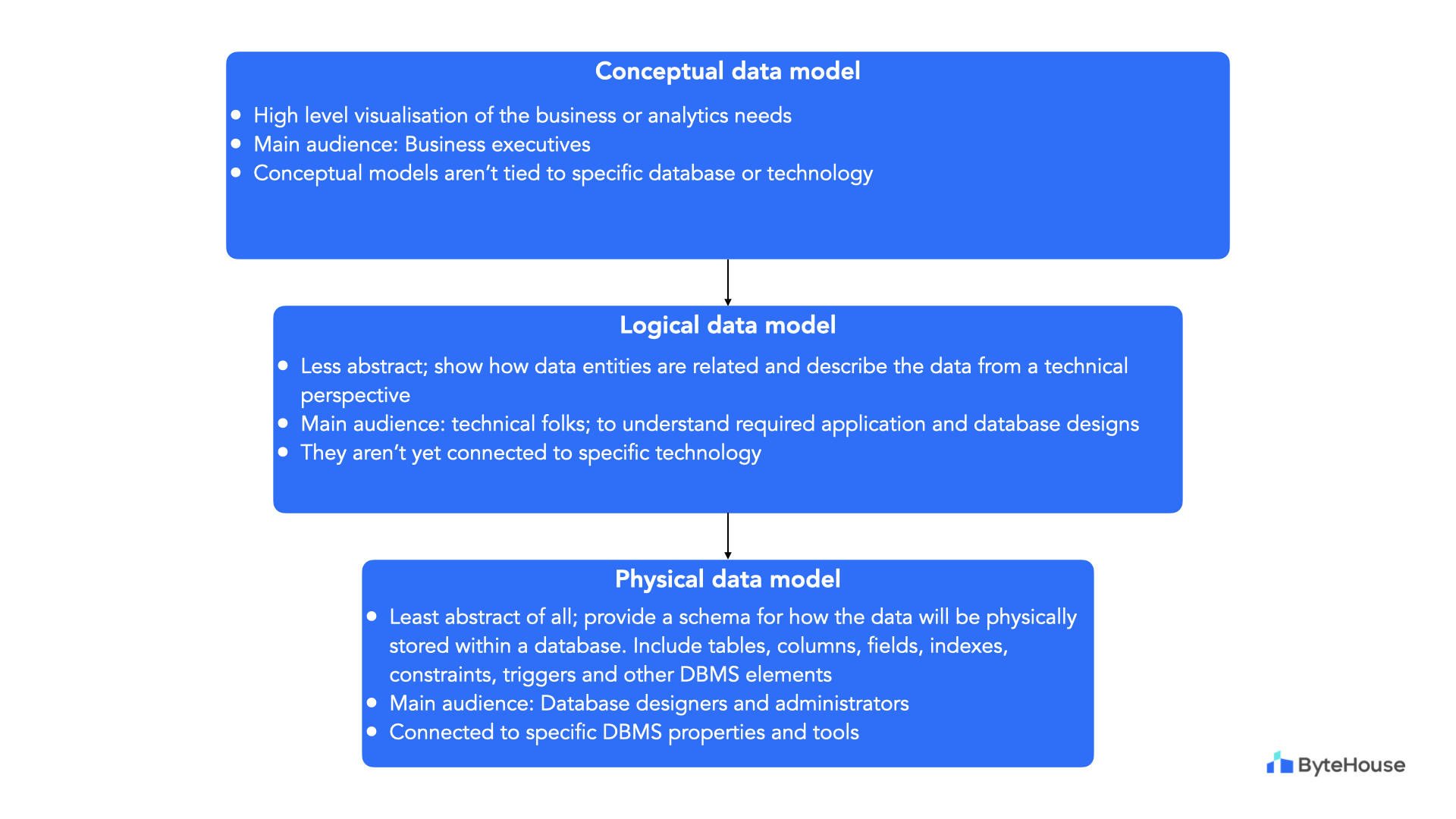 Levels of abstraction in data models
Levels of abstraction in data models
Understanding data modelling is akin to deciphering the language of data, translating raw information into actionable insights. From its fundamental role in creating structured data representations to its diverse types tailored for specific needs, data modelling forms the bedrock of effective data engineering. Moreover, grasping the distinction between data modelling and data architecture illuminates the holistic approach required in building robust, efficient data ecosystems. So, the next time you marvel at a data-driven decision or a seamless database query, remember, it all begins with the art and science of data modelling.