The data modelling process: A step-by-step guide
Part 3 out of 5 of 'Data Modelling: Unlocking Insights, One Model at a Time' series
This blog post is Part 3 of ByteHouse's 5-part series titled Data Modelling: Unlocking Insights, One Model at a Time
This series will cover the following topics:
The data modelling process
Data modelling techniques
Benefits of data modelling
Data modelling, as explained previously, is the process of creating a visual representation of data and its relationships. It is an essential step in developing a database or data warehouse, enabling businesses to transform raw information into actionable insights.
In this comprehensive guide, we’ll walk through the sequential process of data modelling. From identifying business entities to finalising the data model, each step is crucial to ensure accuracy and relevancy in your data analysis.
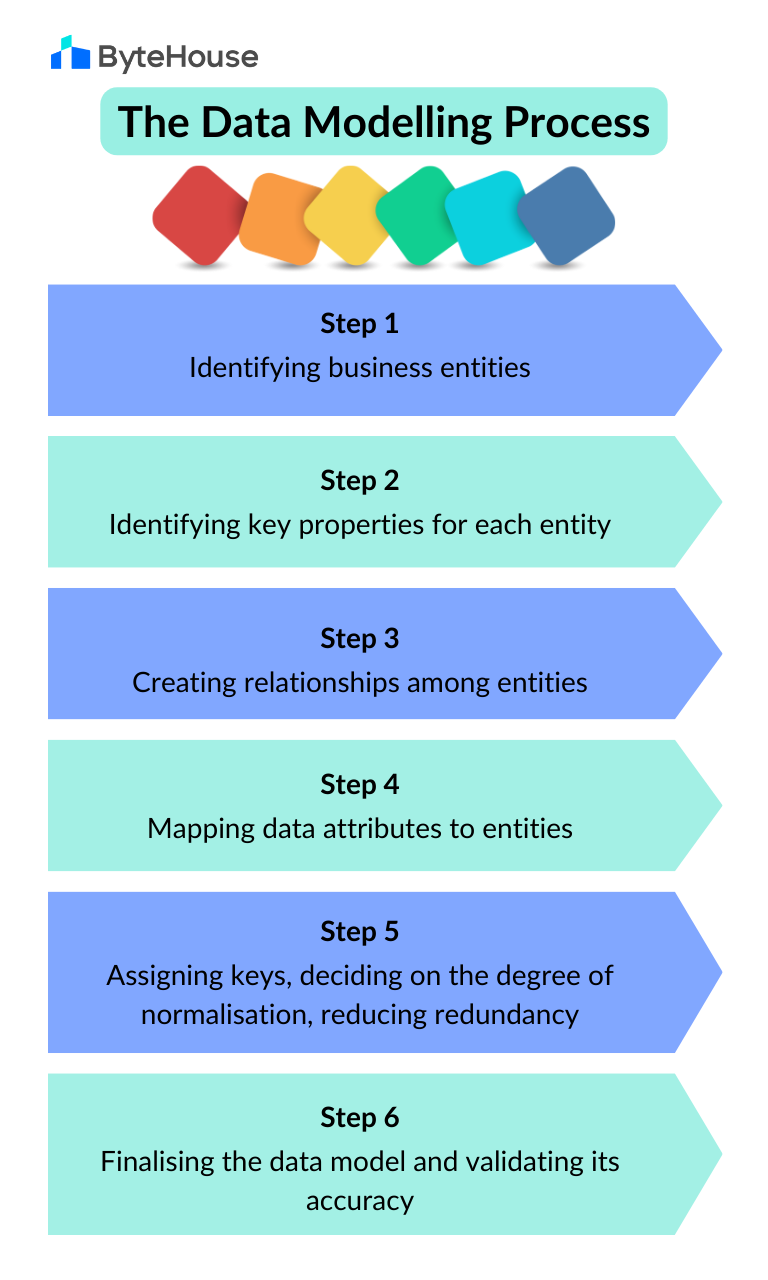
Step 1: Identifying business entities
At the heart of every data model are the business entities—objects or concepts representing real-world items. Identifying these entities is foundational. This can be done by interviewing stakeholders and reviewing business documentation. For instance, in a retail context, entities could be 'Customers,' 'Products,' and 'Orders.' Understanding the core elements of your business sets the stage for a meaningful data model.
Step 2: Identifying key properties for each entity
Once you've identified entities, it's imperative to pinpoint their key properties. The key property is the attribute that uniquely identifies an entity. For 'Customers,' the key property might be the 'customer ID' or 'mobile number'. These properties serve as building blocks for your data model, providing essential information about each entity.
Step 3: Creating relationships among entities
Entities rarely exist in isolation; they interact and form relationships in many ways. Understanding these relationships is pivotal.
The most common types of relationships are one-to-one, one-to-many, and many-to-many.
A one-to-one relationship means that each entity in one set can be related to only one entity in the other set. For example, a customer entity might have a one-to-one relationship with a shipping address entity.
A one-to-many relationship means that each entity in one set can be related to multiple entities in the other set, but each entity in the other set can only be related to one entity in the first set. For example, a customer entity might have a one-to-many relationship with an order entity.
A many-to-many relationship means that each entity in one set can be related to multiple entities in the other set, and each entity in the other set can be related to multiple entities in the first set. For example, an order entity might have a many-to-many relationship with a product entity.
Establishing these connections ensures a holistic view of the business processes and enriches your data model.
The data modelling process
Step 4: Mapping data attributes to entities
With entities and relationships defined, it's time to map data attributes to the corresponding entities. Data attributes are specific pieces of information related to each entity's key properties. 'Customer Name' and 'Order Date' would be data attributes mapped to the 'Customers' and 'Orders' entities, respectively. This mapping ensures that each piece of data finds its place in the model.
Step 5: Assigning keys, deciding on the degree of normalisation, reducing redundancy
There are two main types of keys: primary keys and foreign keys.
A primary key is a column or set of columns that uniquely identifies each row in a table. For example, the customer ID column might be the primary key for the customer table.
A foreign key is a column or set of columns in one table that references the primary key of another table. For example, the customer ID column in the order table might be a foreign key that references the customer ID column in the customer table.
Normalisation is organising data in a way that reduces redundancy and improves data integrity. There are six levels of normalisation, but most databases are normalised to the third normal form (3NF).
Redundancy is the repetition of data in a database. Reducing redundancy can improve performance and simplify maintenance.
Step 6: Finalising the data model and validating its accuracy
Once keys are assigned, normalisation is achieved, and redundancy is minimised, it's time to finalise the data model. This step involves reviewing the entire model, ensuring it accurately represents the business entities, their relationships, and the associated data attributes. Validation is key; using sample data to test the model helps identify discrepancies or inconsistencies. Iterative refinement might be necessary to validate the model's accuracy fully.
Throughout this process, attention to detail and a strategic approach are paramount. Each step, from identifying business entities to ensuring optimal normalisation, contributes to the data model's robustness. By carefully following this step-by-step process and thoroughly validating the model, businesses can create dependable data models. This empowers them to gain a competitive edge in the data-driven world.