How ByteHouse increased ClickHouse's read performance and data modification ability with UPSERT
ByteHouse added the UPSERT function and a self-developed table engine to expand ClickHouse's scope
In June 2016, ClickHouse was made available as an open-source software under the Apache 2.0 license. As we know, it is excellent for data analytics. However, the ByteHouse team identified some shortcomings and solved them. This blog post details the addition of UPSERT* functionality to widen the scope of ClickHouse.
Limitations of ClickHouse’s Native Engine
ReplacingMergeTree, the native ClickHouse engine, uses a Merge-on-Read strategy, similar to LSMTree. When writing, the data is first sorted based on the key and then the columnar files are generated. Each batch of imported data is assigned a version number, indicating the order of data entries.
Data from the same batch does not contain duplicate keys, but data from different batches can. This necessitates merging when reading, returning the most recent version number for data with the same key, known as Merge-on-Read.
ClickHouse, as we know, has excellent data analytics capabilities. However, the ByteDance R&D team observed the following shortcomings:
Complex operation with UPSERT and DELETE
Poor performance with JOIN
Reduced availability at larger cluster sizes
Poor resource separation
As a result, the team optimised ClickHouse to build a more capable data analytics platform. This chapter details the enhancements made to UPSERT.
Merge-on-Read is optimised for writing. Its read performance is relatively poor. This is because key-based merge is single-threaded and difficult to parallelise. Secondly, the merge process necessitates an enormous number of memory comparisons and memory copies. Finally, it causes constraints to presuppose push-down.
There are some variations on this solution, such as keeping some indexes to speed up the merge process and avoid having to perform key comparisons every time you merge.
To summarise, the only available option for native ClickHouse's data append is its ReplacingMergeTree engine, which falls short on business requirements, particularly:
Read performance - Since ReplacingMergeTree employs a write-first mode, there is a significant reduction in read speed. When executing searches compared to other engines, there is a significant performance reduction, and queries utilising ReplacingMergeTree have an excessively high response latency.
Supports only data update - Data removal can only be achieved through the CollaspingMergeTree engine, and if a separate update and delete functionality is made available through a variety of table engines, the system becomes highly complex.
Merge initiates de-duplication in ReplacingMergeTree - De-duplication is not active when the data is imported; it only becomes active within the partitions after a period of time.
ByteHouse Read Optimisation Solution: UniqueMergeTree
To alleviate these problems, ByteDance created UniqueMergeTree in ByteHouse, a table engine that supports real-time update and delete operations.
UniqueMergeTree adopts a Mark-Delete + Insert strategy, which is the opposite of a read-optimised solution. In this scheme, updates are implemented by deleting and then inserting. This solution is detailed as follows using SQLServer column stores.
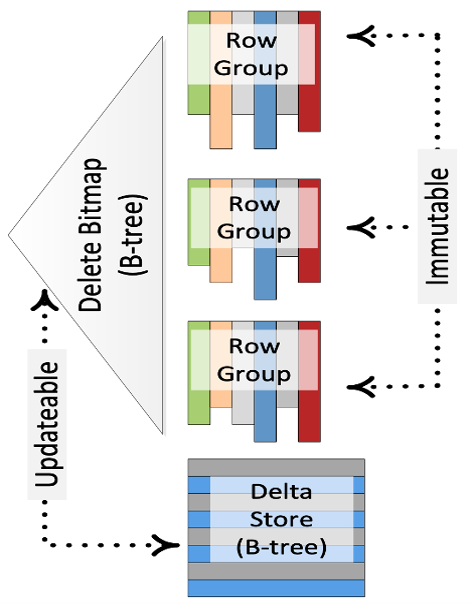
Figure 1. Enhancements to SQLServer Column Stores
As shown in the diagram, each Row Group represents an immutable columnar file, and a Bitmap, i.e., Delete Bitmap, is used to record the row numbers marked for deletion in each Row Group. When processing updates, the Row Group to which the key belongs and its row number in the Row Group are first looked up, and the Row Group's Delete Bitmap is updated. Finally, the updated data is written into the Delta Store.
When querying, the scanning of different Row Groups can be in parallel, and only the data belonging to the Delete Bitmap needs to be filtered out based on the row number.
This solution balances the performance of write and read. On the one hand, the exact location of the key is located when writing, and on the other, write-write conflicts are dealt with.
A variation of this solution is - instead of looking up and updating the location of the key when writing, the key is first recorded in a buffer, which is subsequently transformed to a Delete Bitmap using background processes and then the incremental key in the buffer is processed by merge-on-read when querying.
Performing UPSERT and DELETE
First, we create a UniqueMergeTree table with the same parameters as ReplacingMergeTree. The difference being that the UniqueMerge table can be identified with UNIQUE KEY constraints, either through multiple fields or expressions.

UPSERT will be used in the subsequent write operations in the above table. For example, we write four sets of data on row 6, which only contains two keys, 1 and 2, so for the select operation in row 7, each key will only return the highest version of the data. For the write operation on row 11, key 2 is an existing key, so the name corresponding to key 2 is updated to B3; key 3 is a new key, so it is inserted directly. For the row delete operation, we have added a virtual column “delete_flag”, which allows the user to mark which batch is to be deleted and which is to be upserted.
Highlights of ByteHouse’s UPSERT
For unique table writes, we will use UPSERT command; inserting rows into a database table if they do not already exist, or updating them if they do.
Users can enable or disable the row update mode and partial column update mode of the UniqueMergeTree table engine based on their specific business needs.
ByteHouse also supports deleting data by specifying the value of the Unique Key to meet the requirements of real-time row deletion. The issue of earlier version data overwriting newer version data that might happen in backtracking scenarios can be resolved by specifying a version field.
ByteHouse also supports data synchronisation across multiple copies to avoid a single point of failure in the overall system. ByteHouse tested the write and query performance of UniqueMergeTree (importing 10 million rows of data: a total of 10 parts).
As shown in the table, UniqueMergeTree achieves significant improvement in query speed when compared to the ReplacingMergeTree, despite a minor decline in WRITE performance. We further compared the query performance of the UniqueMergeTree with that of the regular MergeTree and found that the two are very similar.
Real-time User Profiling
User profiling is prevalent in the e-commerce industry. Originally, offline profiling mode updated data in a T+1 manner and not in real time. With real-time tagging, ByteHouse has developed the ability to profile users in real time on the data management platform. The main data link is shown below.

To ensure that the services are simultaneously supported by offline and real-time data, wide tables are created in ClickHouse after tags are accessed.
UniqueMergeTree operation perfectly meets the requirements of real-time user profiling scenarios while the original architecture remains unchanged:
Updates with UPSERT are enabled by configuring the Unique Key and the latest value corresponding to each Unique Key is automatically returned
Performance: A single shard can ingest up to 10k+ rows/s; Query performance is almost the same as that of a ClickHouse native table
Support real-time data deletion per Unique Key
Additionally, ByteHouse supports several other features through UniqueMergeTree
Unique Key support for multiple fields and expressions
Support for both partition-level and table-level uniqueness
Support for custom version fields; earlier version of data is automatically ignored when writing
Support for multi-copy deployment, with asynchronous replication to ensure data reliability
Apart from real-time user profiling scenario, the UPSERT functionality offered by ByteHouse has served many applications including thousands of online tables.
*UPSERT = (‘update’ + ‘insert’); updates an existing row if a value already exists in a table, and inserts a new row if it doesn’t.