How ByteHouse augments ClickHouse's query performance using optimised multi-query join
ByteHouse increased ClickHouse's QPS by optimising the multi-query join with stage-by-stage approach
The development of data analytics is a continuous search for effectiveness and flexibility. Efficiency is very important, but it is not something that needs to be increased indefinitely.
The query latency of 1 second presents a very different challenge from that of 1 minute, where the performance improves dramatically. However, for most applications, the user experience may not be significantly enhanced if we try to achieve a query latency of 0.1 seconds from 1 second. Thus, analytical flexibility is extremely crucial depending on timeframe requirements.
Data analytics has evolved over time. In its early stages, it relied on immutable tables featuring infrequent format modifications, custom development, and immutable query processing. Immutable tables cater to situations when business and data requirements are relatively constant. A wholly immutable query processing, however, is unable to effectively extract the value of data in today's world.
By allowing flexible data analysis, we can assist businesses examine the correlation between diverse data, immediately identify the causes of issues, and significantly increase productivity.
Limitations of wide tables
As data analytics evolved, a cube model based on precomputation of summarised data was proposed. By gathering the data with ETL (Extract, Transform, Load) tools and creating data cubes, a certain degree of analytical flexibility was achieved while ensuring quick analytical results. Since dimensions of the data cube were fixed, and it was impossible to query the detailed data after data aggregation, it was still not possible to execute ad-hoc queries.
In recent years, ClickHouse brought about the trend of wide table analysis with powerful performance on a single table. The wide table is generated during data processing by joining multiple tables through a number of shared fields, enabling analysis on a single table. The wide table model, supported by ClickHouse's query performance on a single table, could improve the timeliness of analysis as well as the flexibility of data query and analysis operations, which is now a very popular model.
However, wide tables still have limitations such as:
The data developer must put in a lot of effort to generate each wide table, which is time-consuming
Generating wide tables creates a lot of data redundancy
So, how do we improve upon this?
If ClickHouse-based query performance on multiple table joins is good enough, is it possible to skip the step of "flattening data into wide tables" and just manage the interface for external services, so that any business personnel's needs can be directly met by implementing a direct join query on site?
ByteHouse's enhanced query performance on multiple table joins
ClickHouse's execution is simple, with its query mode divided into 2 stages.
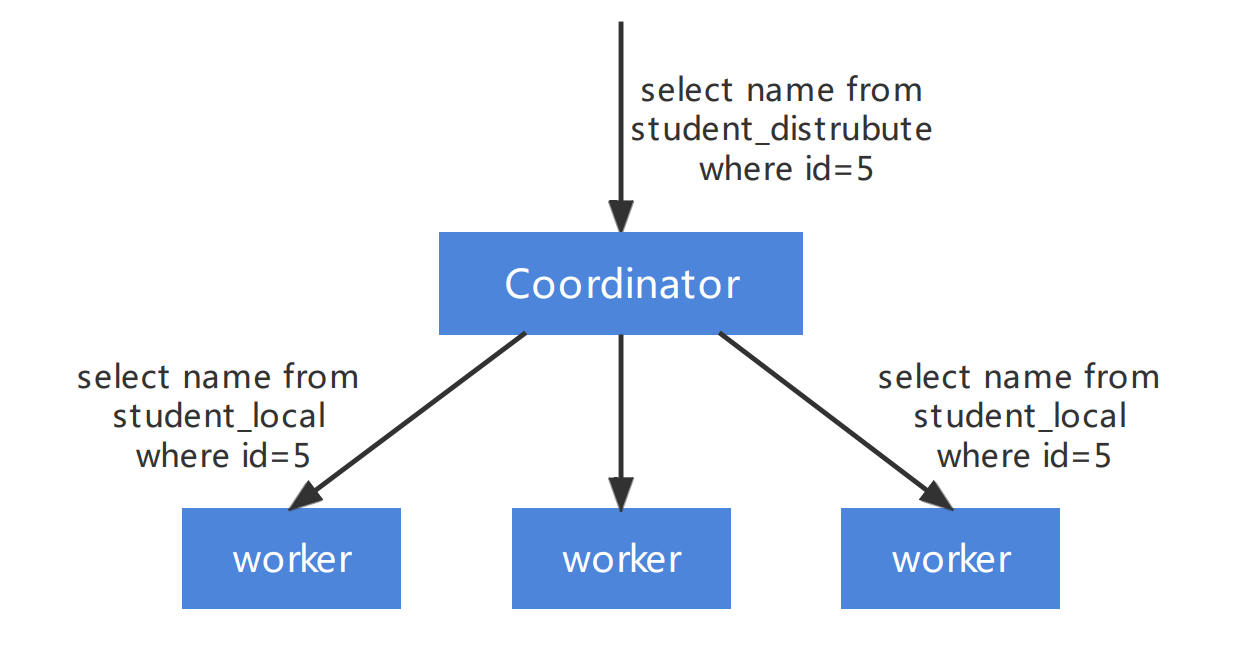 Figure 1. ClickHouse’s 2 stage query mode
Figure 1. ClickHouse’s 2 stage query mode
ByteHouse's multi-table query adopts a stage-by-stage approach, replacing the current two-stage execution of ClickHouse. A complex query is divided into multiple stages based on the data exchange scenario, and data exchange between two stages is completed through exchange.
There is no data exchange within a single stage. There are three main forms of data exchange between stages:
Shuffle based on a single (or multiple) key
Convergence of 1 or more nodes into 1 node (we call it 'gather')
Copy the same data to several nodes (also known as broadcast)
Within each stage, the underlying ClickHouse execution will be reused. The various modules are designed to meet the following goals:
Each module interface must minimise interdependence and coupling, implying that changes to one module don't affect other modules, e.g. adjustments to the stage generation model shouldn't affect the coordinating model .
A plug-in architecture, allowing them to support different policies flexibly based on their configuration.
Depending on the size and distribution of the data, ByteHouse supports a variety of JOIN query strategies, including:
Shuffle Join, the most basic type of join
Broadcast Join, which reduces transmission of the left table by broadcasting the right table to all worker nodes of the left table
Colocate Join, which reduces transmission of left and right tables if the left and right tables have the same join key-based distribution style
The Join operator is usually the most time consuming operator in an OLAP engine. If you want to optimise the Join operator, you can do so by using better hash table implementations. Hash algorithms with better parallelism improve its performance by minimising the amount of data involved in the Join calculation.
Runtime Filter is more effective in some scenarios, especially in the star schema where fact tables join dimension tables. Because the fact table is usually larger in this case, and most of the filter conditions are on the dimension table, the fact table may have to join the dimension table in full.
Runtime Filter works by significantly reducing data transmission and computing by filtering out the input data that does not match the join in advance for the probe side (i.e. the left table), thus reducing the overall execution time. The following diagram shows an example.
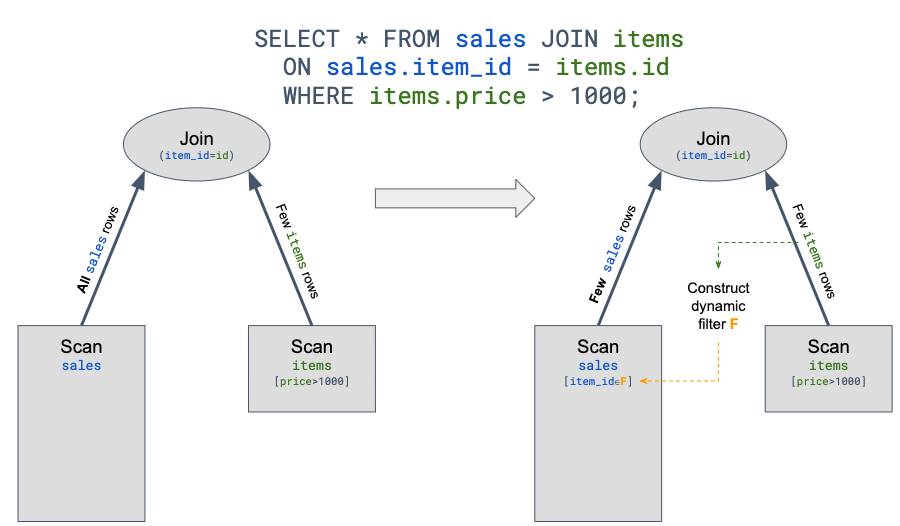 Figure 2. Example of how a runtime filter works
Figure 2. Example of how a runtime filter works
The improved results
SSB 100G test set was processed using ClickHouse version 22.2.3.1 and ByteHouse version 2.0.1, respectively, using the same hardware platform , without creating a wide table. Results are shown in the chart below. Here, no data means no results returned or the latency is over 60 seconds.
As you can see, in most tests, ClickHouse reported an error and failed to return results, while ByteHouse consistently gave results within 1 second.
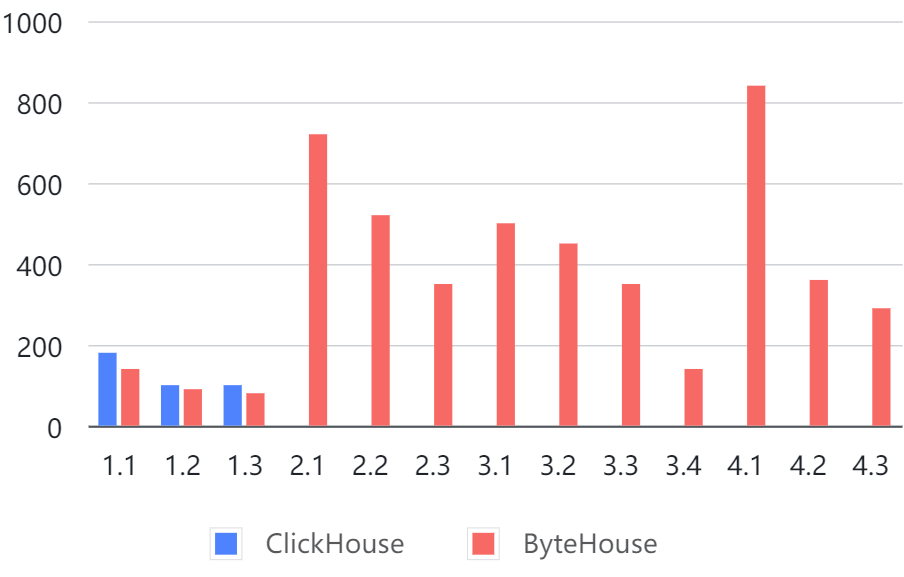
Figure 3. SSB multi-table test (Unit - ms)
Let's show two specific cases that demonstrate the effect of optimisation:
Case 1: The right table of Hash Join is a large table
After optimisation, query execution time was reduced from 17.210s to 1.749s. The lineorder is a large table, which can be shuffled to each worker node based on the join key, reducing the pressure associated with the creation of the right table.

Case 2: A 5-table join (Turn runtime filter off)
After optimisation, query execution time was reduced from 8.583s to 4.464s.
You can begin querying while simultaneously creating all right tables. In order to compare with the current schema, ByteHouse does not enable runtime filter here, which would be faster if it were turned on.

ByteHouse is able to handle all business types more thoroughly thanks to the improved multi-table join query performance. Users may decide whether to put the data into a wide table depending on query scenarios, and all of them can enjoy a great analysis experience.