Case Study: Real-time Advertisement Placement Using ClickHouse
A quick case study on handling advertising placement data using ClickHouse
Today, we'll explore how we handle advertising placement using ClickHouse.
The operation staff needs to view the real-time effect of advertising placement. Because of the characteristics of the business, data collected in one day is often mixed with that collated from the past few days. We originally implemented this system based on Druid. However, we discovered Druid had some flaws in this case.
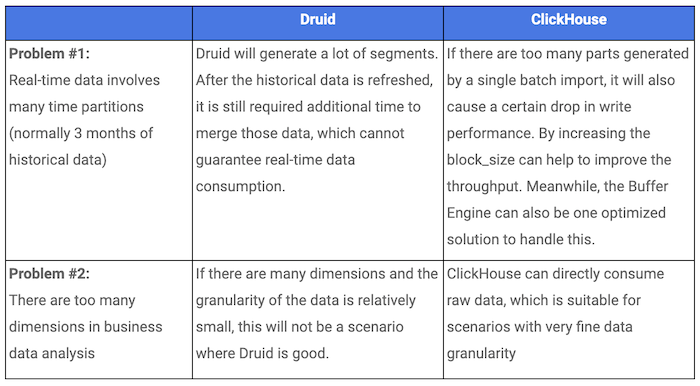 Druid vs. ClickHouse
Druid vs. ClickHouse
ClickHouse could resolve most of the problems faced by Druid. However, there were some challenges left.
Challenge #1: Buffer engine is unable to work with ReplicatedMergeTree
Problem
Clickhouse community provides Buffer Engine to solve the problem of generating too many parts in a single write, but it does not work well with ReplicatedMergeTree. The Buffer written for different Replicas only caches the newly written data on their respective nodes, resulting in inconsistent queries.
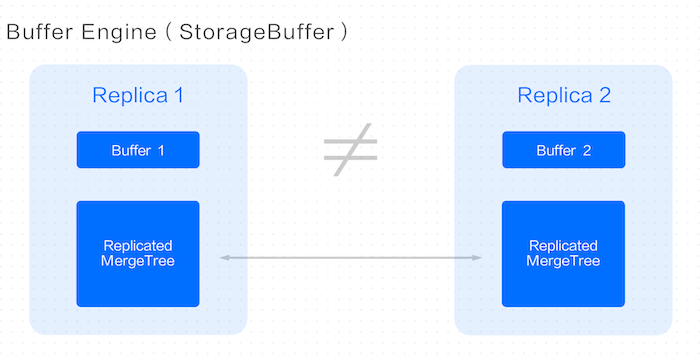 Buffer Engine
Buffer Engine
Solution
We made the following enhancements to the Buffer Engine:
Combine the Kafka/Buffer/MergeTree tables together to provide APIs that are easier to use.
Buffer is built into the Kafka engine, it can be turned on/off as an option, which is easier to use.
Use internal pipeline mode in Buffer table to handle multiple blocks.
Support queries in ReplicatedMergeTree Engine.
Our solution ensures that only one node is consumed for a pair of replicas, so only one out of two Buffer tables has data. If a query is sent to the unconsumed replica, a special query logic is built to read data from the Buffer table of the other replica.
Result
Enhanced Buffer Engine solved the problem of query consistency when Buffer Engine and ReplicatedMergeTree are used at the same time.
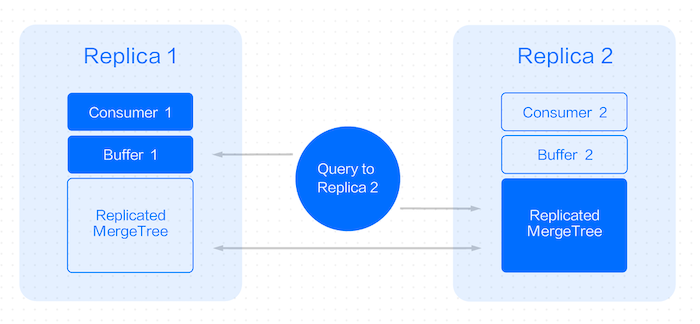
Challenge #2: Data loss and duplicate consumption after downtime
Problem
ClickHouse lacks transactional support. During service downtime, some parts of the batch write operations to ClickHouse might be lost or engaged in double consumption. This is due to the lack of transaction protection when the service is restarting.
Solution
With reference to Druid's KIS solution, we manage Kafka's Offset by ourselves. To achieve the atomic semantics of single batch consumption/writing the implementation chooses to bind Offset and Parts data together to enhance the stability of consumption. During each consumption, a transaction is created by default, and the transaction is responsible for writing Part data and Offset to disk together. If there is a failure, the transaction will roll back the Offset and the written part, then consume again.
Result
Atomicity of each inserted data is ensured along with enhanced stability of data consumption.
By implementing the above listed solution, we could overcome the challenges we faced while using ClickHouse.